
Why Starfish Matters

A Technical Deep Dive into the New IOTA Consensus
padding: 12px;
background: var(–button-shadow-color-normal);
border-radius: 8px;
“>
TL;DR:
Last week we published an overview of the Starfish mainnet launch. This post, written by Sebastian Mueller of the IOTA Foundation’s Research team, goes deeper: the technical design decisions behind Starfish, why they matter, and what the first mainnet metrics show.
Starfish is now enabled on IOTA Mainnet. The v1.21.1 Mainnet release introduced protocol version 24 and enabled Starfish consensus on Mainnet.
That is the release-note version.
The research version is more interesting: Starfish is an attempt to fix a part of DAG-based Byzantine consensus that has often been treated as plumbing, even though it shapes the whole protocol. That part is dissemination.
Looking for the broader picture first? Read our introduction to the Starfish Mainnet launch.Consensus is usually described as an agreement problem. A group of validators has to agree on one history, even when messages are delayed and some participants may be Byzantine. That framing is correct, but it hides a practical constraint: a validator cannot vote on a block it has not seen, cannot certify data it cannot reconstruct, and cannot help the protocol make progress if the information it needs is always arriving one request too late.
So beneath the agreement problem there is a synchronization problem. How does the right information reach the right nodes quickly enough? That is the question I think Starfish answers in a cleaner way than previous (uncertified) DAG protocols.
DAG-based BFT protocols make this question unusually visible. A DAG – a directed acyclic graph – is not just a way to arrange blocks. It is a record of mutual knowledge. Each new block points back to earlier blocks the validator has seen. If many validators reference the same block, the network is converging around shared information. If references are missing, the DAG exposes the gap.
In that sense, the DAG is not merely a commitment structure. It is a synchronization structure.
This is why dissemination matters so much.
The idea that dissemination should be carried inside the protocol itself – rather than handled by a separate broadcast layer – has a clean name in the literature: cordial dissemination. The Cordial Miners paper (Keidar, Naor, Shapiro — DISC 2023) gave it a formal treatment. Participants do not only gossip their own blocks; they forward what they believe other honest parties need in order to keep up.
There are two basic strategies for being cordial.
The first is pull. A validator asks for missing blocks only after it discovers that it needs them. Pull is efficient in a narrow sense: nothing is sent unless it is requested. But it is bad for latency, because every missing block introduces another request-response round trip. Worse, under load, pull can amplify the problem it is trying to solve. Slow validators issue more requests. Fast validators spend more bandwidth answering them. The network becomes busiest exactly when it needs to recover.
The second strategy is push. Validators proactively forward information that others are likely to need. Push is better for latency because the data is often already present when the recipient discovers that it needs it. But naïve push is expensive. If every validator pushes full blocks to every other validator, bandwidth grows quickly with the validator set.
This is the old tension: pull is lean but late; push is fast but heavy.
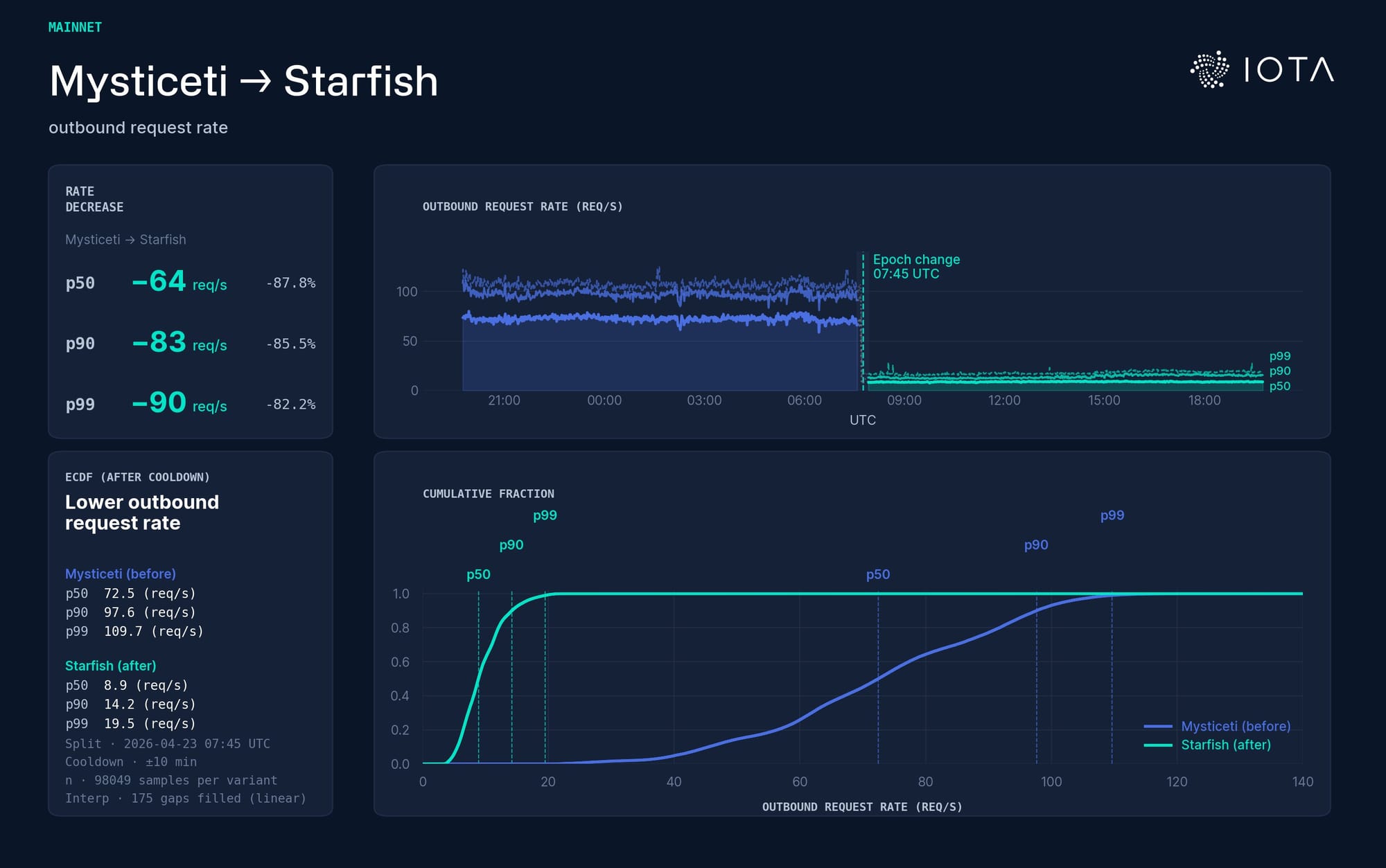
Outbound request rate – a push-vs.-pull signal: Mysticeti (blue) vs Starfish (green). Outbound requests are the pull path: a validator realizes it is missing something, asks a peer for it, and waits. Pull is bandwidth-efficient, but it is a bad place to put latency because it happens after the gap already exists. Post- Starfish, outbound requests drop by roughly an order of magnitude — validators stop far less often to recover missing history on the critical path.This is one of the main things Starfish was designed to change.
The first design move is to separate metadata from payload. Metadata is the part consensus needs immediately: references, votes, acknowledgments, timing, and commitments. Payload is the transaction data. Previous DAG designs often carried payload too tightly along the consensus path. That makes the protocol fast in small settings, but it becomes expensive as throughput grows.
Starfish keeps the consensus path light. Block headers carry the consensus-relevant structure and a commitment to the payload, while the payload itself is handled separately.
This lets the protocol push the small thing aggressively – the header – without pushing the heavy thing in full.
The second design move is Reed-Solomon encoding. Reed-Solomon coding is the same idea that lets QR codes survive scratches and CDs survive scuffs: take some data, produce a number of pieces with carefully designed redundancy, and arrange it so the original can be rebuilt from any sufficient subset of the pieces — even if the rest are missing. In Starfish, a block’s transaction data is broken into fragments – one per validator – with enough redundancy that a small subset of valid fragments can reconstruct the whole.
One distinction worth being careful about: the reconstruction threshold is not 2f+1 fragments. The Reed–Solomon code is set up so that any f+1 valid fragments are enough to reconstruct the payload. The 2f+1 number appears in the availability certificate: if 2f+1 validators acknowledge availability, then even if up to f of them are Byzantine, at least f+1 honest validators must hold valid fragments — which is enough for reconstruction.
0:00
That distinction matters. Availability is not “everyone already has the full data.” Availability is “the network has enough verified pieces that honest validators can recover the data.”
The Data Availability Certificate, or DAC, is especially elegant. A validator acknowledges in its own header that it has verified a payload from some earlier block. Once 2f+1 such acknowledgments are reachable in the causal history of a later committed block – meaning you can reach them by walking backward through the block’s references and the references of those references – that later block acts as a certificate of availability for the earlier payload.
There is no separate availability round bolted onto the protocol. Availability accumulates as the DAG grows.
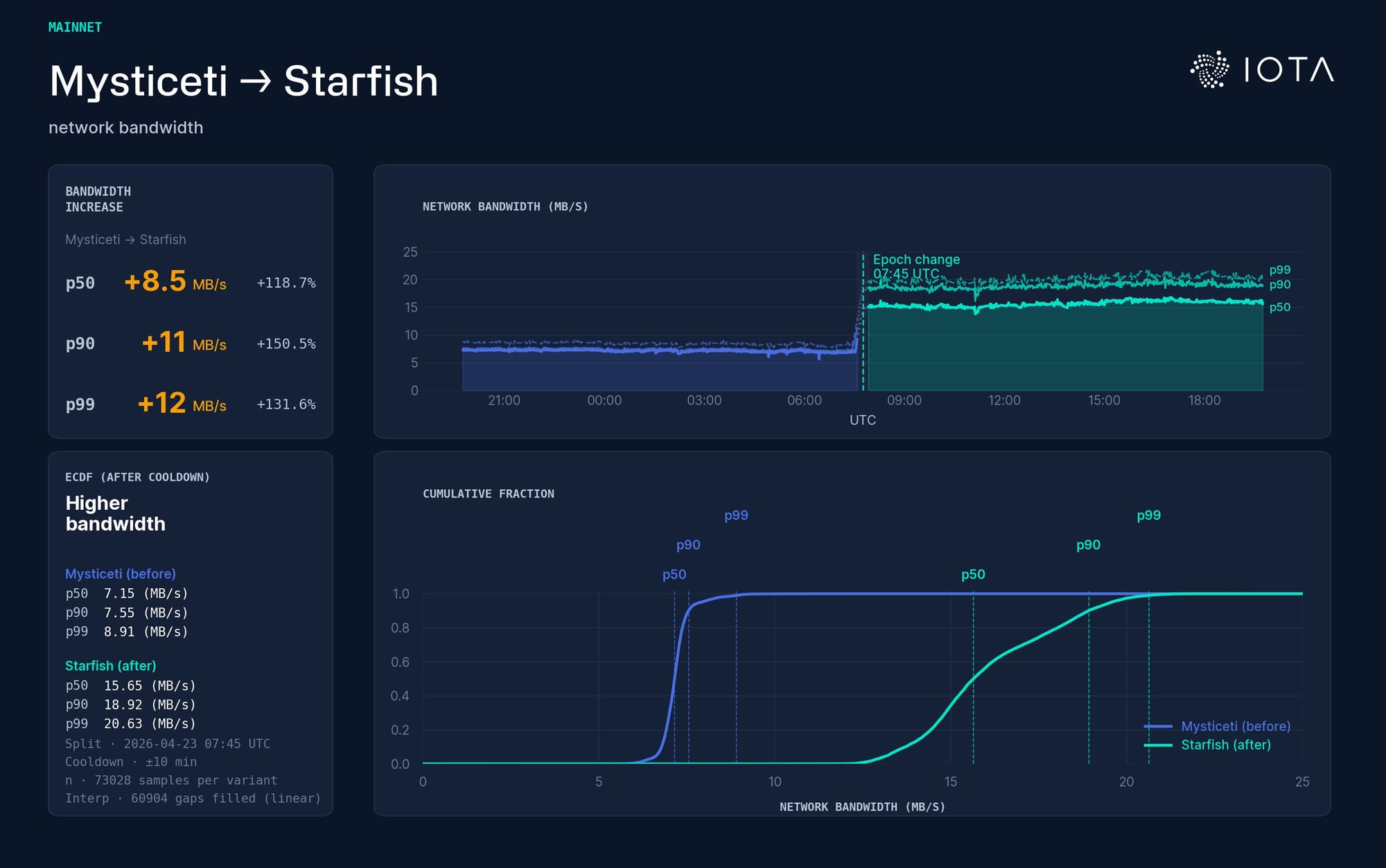
Bandwidth: Mysticeti (blue) vs Starfish (green). Starfish uses roughly twice the bandwidth in this window. This is structured communication – not naive full-payload flooding – spent upfront so the protocol avoids recovery costs later.
The same graph that records ordering also records recoverability. The same communication that moves consensus forward also carries the evidence that payloads can be reconstructed.
This is different from treating dissemination as an implementation detail. In Starfish, dissemination is part of the consensus design.
Uncertified DAG protocols are attractive because they avoid per-block quorum certificates. That is one reason protocols such as Mysticeti can achieve very low latency. Prior uncertified DAG protocols lacked rigorous liveness proofs, and recent work showed desynchronization attacks in which honest parties could fail to commit leaders even after the network had stabilized.
The vulnerability is subtle but important. Honest parties could advance rounds without creating their own blocks. That leaves holes in the DAG. Enough holes, and the protocol may not have the structure it needs to commit leaders, even after the network becomes synchronous again.
Starfish fixes this with a Push pacemaker. The intuition is simple: nothing advances empty.
A party has to create its own block before advancing to the next round. A lagging party can catch up once it sees a quorum of current-round blocks. This prevents validators from drifting ahead without contributing the blocks that later serve as votes and certificates.
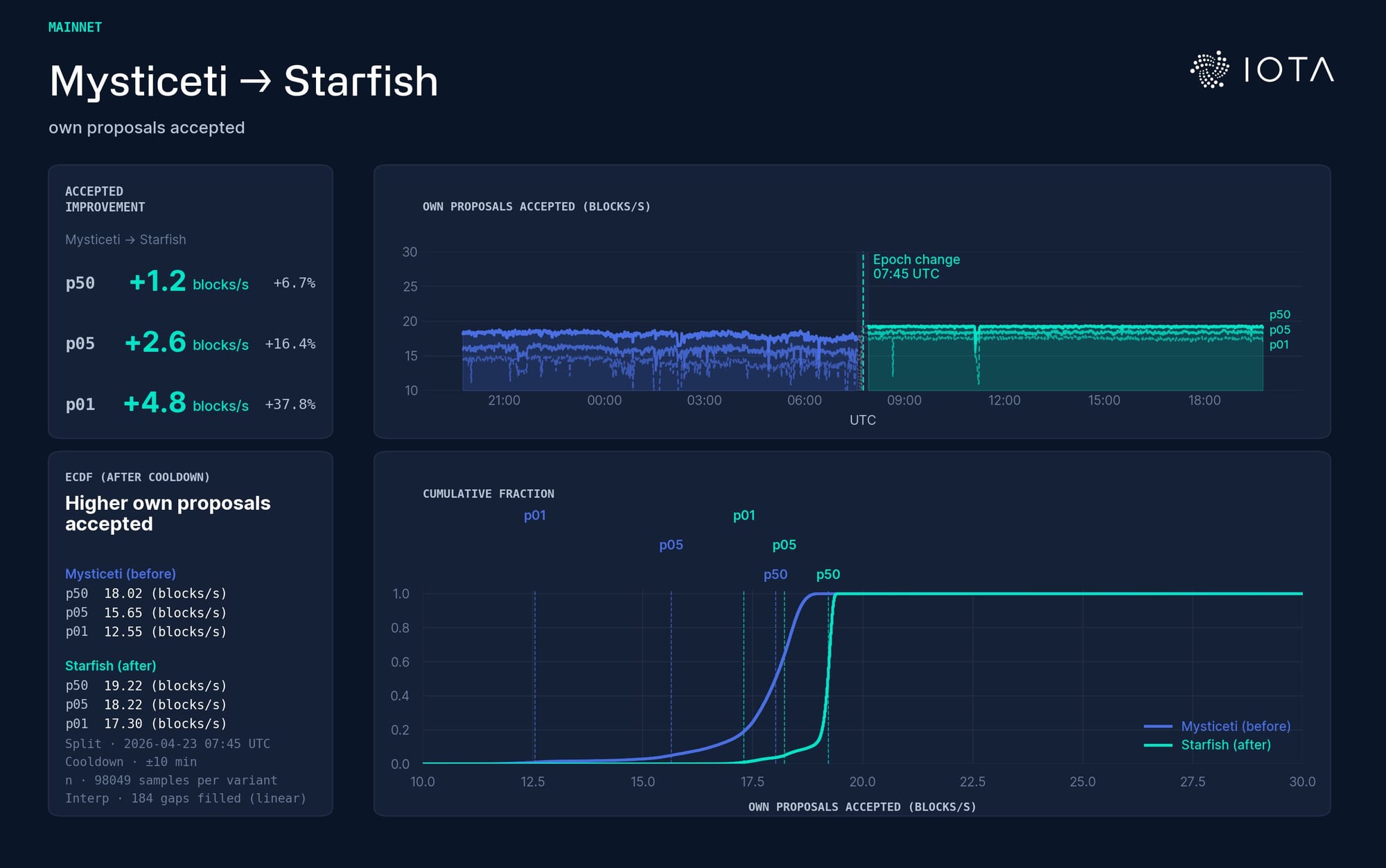
This graph shows how consistently validators get their own proposals accepted into the consensus rhythm. Mysticeti (blue) vs Starfish (green). The variance of the acceptance rate drops drastically and validators recover quickly.
This is not only a cosmetic or theoretical change. The pacemaker is part of the protocol’s meaning. It says progress is not just a matter of local timeouts; progress requires the DAG to stay structurally healthy.
Performance
A lot of consensus discussion collapses into peak throughput and median latency. Those numbers are useful, but they are not enough. The more important production question is usually about variance. How wide is the latency distribution? How often do commits land in the tail? What happens when validators are slow but not faulty? What happens when the network has to recover?
This is the same insight industrial quality control has had for a century. Shewhart charts, statistical process control, Six Sigma: they all point in the same direction. The first thing you control is variance. A factory is not called in control because its average output is good; it is in control because its output stays inside a predictable band. Reliability, in every engineering discipline that takes reliability seriously, is written in the language of distributions, not means.
Distributed ledgers have not fully absorbed that lesson yet. Benchmarks publish averages and peaks; they rarely publish tail latency, jitter under load, or the full distribution of commit times during a disturbance – exactly the quantities that tell you how a system behaves in the real world.
If I had to write a short list of robustness metrics I wish every consensus paper reported, it would look like this:
- The full distribution of commit latency, not just the mean, across a long run
- The 95th and 99th percentile commit time under a chosen load
- The variance of TPS when some fraction of honest nodes is slow but not faulty
- The time to recover nominal latency after a partition heals
- The standard deviation of round duration under adversarial scheduling.
None of these are hard to measure. They are hard to commit to, because they expose failure modes that the averages hide. Systems built to look good on averages tend to be brittle on the tails. Systems built to keep variance low tend to feel, subjectively, a great deal more solid, even at slightly higher mean latency.
Starfish’s design choices read well through this lens. The push pacemaker exists to reduce the variance of round duration under stress. The DAC-on-DAG construction removes a source of variance in availability certification. The shard-based payload push reduces the bandwidth variance as the validator set grows. Even the extra commit round is, in part, a variance trade: a slightly higher mean latency bought in exchange for a tighter distribution under load.
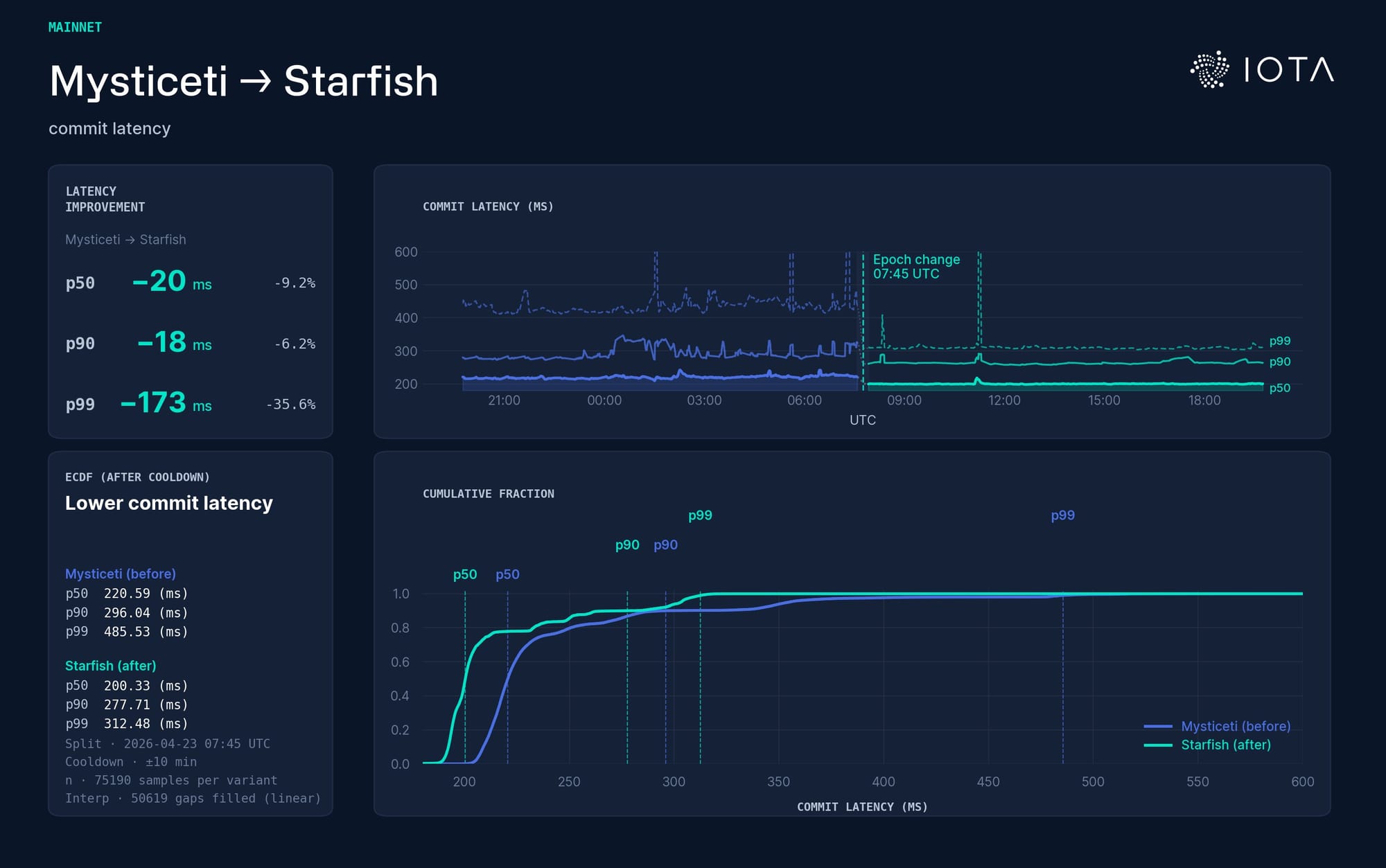
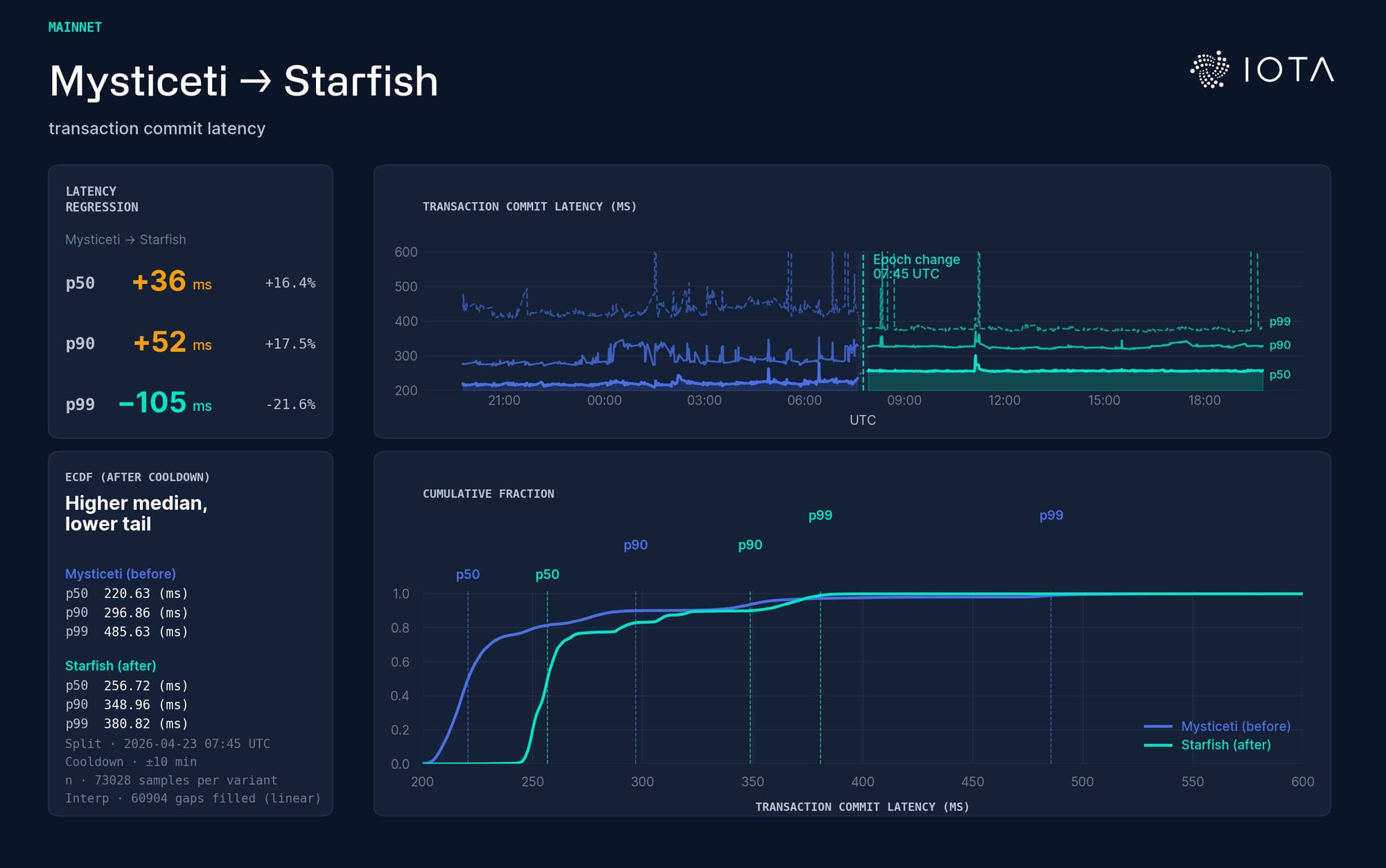
Commit latency: Mysticeti (blue) vs Starfish (green). The top panel plots p50, p90, and p99 over time. For example, p99 means that 99% of observations are at or below that line, and 1% are above it. The main signal is the tail: The median improves a bit, but the p99 improves much more: roughly 486 ms → 312 ms. The tighter ECDF curve confirms the robustness story: fewer slow commits, not just a better average.
Transaction commit latency: Mysticeti (blue) vs Starfish (green). As expected, the median and p90 move up slightly; p99 moves down. Starfish adds an availability step before sequencing, so the ordinary clean case pays a small additional cost. But the slow cases improve.
Low variance is the design goal that keeps showing up under the hood, and it is the right goal for a ledger that is meant to be robust rather than merely impressive on a benchmark slide.
Some Continuity
There is a continuity here that I like. The original IOTA Tangle had a cooperative intuition: participation meant helping the ledger grow. A new transaction did not merely ask the network to accept it; it also approved previous transactions. The mechanism is very different from modern BFT consensus, but the underlying instinct is recognizable.
The honest move is to help the network advance.
Starfish gives that instinct a Byzantine-fault-tolerant form. Validators do not just propose their own blocks. They help keep others synchronized. They acknowledge availability. They carry forward the causal evidence that the system needs to make progress.
This is also why the DAG matters. In a chain, the structure mostly tells you what came next. In a DAG, the structure also tells you what was known, by whom, and when. Starfish uses that extra information not only for ordering, but for availability and liveness.
Real-World Consensus
Mainnet launch is the operational milestone. The deeper milestone is that this design has moved from paper and test environments into the kind of setting where the tradeoffs matter. Real validator networks are uneven. They are geographically distributed. They have heterogeneous machines, variable links, transient delays, and occasional bad behavior. Consensus protocols are not judged only by how they behave in the clean case. They are judged by how they degrade, how they recover, and how much useful work they can keep doing while conditions are imperfect.
Starfish is built around that reality. It does not pretend dissemination is secondary. It does not hide availability behind a separate abstraction. It does not assume synchronization as a free background condition. It makes these things explicit.
That is why I think Starfish matters – not because it’s simply “faster,” although performance matters. It matters because it makes the dissemination story as serious as the safety story.
And in distributed systems, that is often where the real protocol lives.
Source link





